II.
Статистические
критерии.
1.
Статистические критерии. Параметрические и
непараметрические критерии.
В настоящем пособии будут
рассмотрены следующие непараметрические
критерии:
8. l -
критерий Колмогорова-Смирнова.
9. Критерий j* -
угловое преобразование Фишера.
1.
Параметрическими называются
те статистические критерии, которые используют в процессе расчетов параметры
распределения, то есть средние значения и дисперсии (среднеквадратические
отклонения). Помимо этого, должно выполняться требование соответствия
эмпирического распределения нормальному распределению (по крайней мере, с
известной степенью приближенности). Существуют способы проверки такого
соответствия, например, . χ2 - критерий Пирсона. Примером
параметрического критерия может служить
t – критерий Стьюдента, позволяющий непосредственно оценивать различия в
средних между двумя выборками (сравнивать среднее
значение выборки с каким-либо заданным числом).
Непараметрическими называются критерии, не включающие в формулу расчета
параметры распределения, и оперирующие частотами или рангами. Последующие
критерии, представленные в настоящем пособии относятся к
непараметрическим.
Подробнее о преимуществах и недостатках
параметрических и непараметрических методов можно прочесть в (1), стр.27.
Критерии, описанные в настоящем пособии, будут
представлены в соответствии со следующей схемой:
- назначение критерия;
- описание критерия;
- форма представления нулевой и альтернативной
гипотез;
- ограничения критерия (требования, предъявляемые к
выборке);
- графическое представление критерия (где это
необходимо);
- алгоритм расчета критерия.
Для
каждого из типов исследовательских задач будет представлено по 2 критерия (кроме критерия j* - угловое преобразование Фишера), отличающихся по мощности, то есть – способности
выявлять достоверные различия.
2.
Назначение
критерия.
Критерий используется для оценки различий между двумя выборками по уровню какого-либо признака, измеренного количественно. В каждой
из выборок должно быть не менее 11 испытуемых (значений).
Описание
критерия.
Непараметрический критерий, позволяющий оценить различие между двумя выборкам и по уровню
какого-либо признака. (Невыявленность достоверных различий с помощью этого
критерия, строго говоря, не означает их
отсутствия, а указывает на необходимость применения более мощного критерия,
например j* Фишера.) Если Q – критерий выявил достоверное различие с уровнем
значимости p<= (меньше или равно) 0,01 –
можно ограничиться только его применением.
Критерий применим в тех случаях, когда данные
представлены, по крайней мере, в порядковой шкале. Признак должен варьировать в
некотором диапазоне значений – в противном случае применение критерия
невозможно. Например, если имеется только 3 значения признака – Х1, Х2, Х3 – установить различия очень трудно. Метод
Рзенбаума требует, соответственно, достаточно тонко измеренных признаков.
Применение критерия начинается с упорядочивания
значений признака в обеих выборках по нарастанию (или убыванию). (Для удобства
каждое значение можно представить на отдельной карточке с целью их последующей
систематизации.) Далее становится видно, совпадают ли диапазоны значений. Если
нет, то определяется, насколько один ряд «выше» - S1, а другой «ниже» - S2. Чтобы избежать путаницы, рекомендуется первым рядом
считать тот, где значения выше, а вторым – тот, где ниже.
Гипотезы:
Но: Уровень признака в выборке 1 не превышает уровня
признака в выборке 2.
Н1: Уровень
признака в выборке 1 превышает уровень признака в выборке 2.
Графическое представление критерия Q.
А) Б) В)
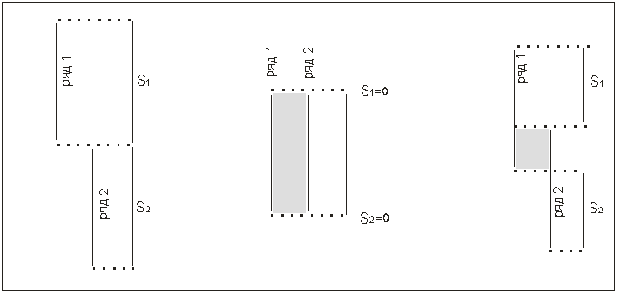
Рисунок 5
В
варианте А) все значения первого ряда выше всех значений второго. Различия, безусловно,
достоверны (при условии, что n1 и n2 больше или равно 11).
В
варианте Б) оба ряда находятся на одном и том же уровне => различия
недостоверны.
В
варианте В) ряды частично пересекаются, но все же первый ряд оказывается
гораздо выше второго. Величина Q равна
сумме S1 и S2. Чем она
больше, тем достовернее различия. (Находится из таблиц.)
Ограничения критерия Q.
В каждой из выборок должно
быть не менее 11 наблюдений.
Объемы выборок должны
примерно совпадать:
Меньше 50 наблюдений –
разница не более 10;
От 50 до 100 наблюдений – не
больше 20;
Больше ста наблюдений, то
одна из выборок не должна быть больше другой более чем в 1,5 – 2 раза.
Диапазоны разброса значений в
двух выборках не должны совпадать между собой, иначе применение критерия
бессмысленно.
Пример.
Дано: индивидуальные значения
показателя интеллекта в двух группах испытуемых. Можно ли считать, что одна
группа превосходит другую по показателю интеллекта?
1. Выбираем ряд, который
предположительно выше по показателям (например, группа 1) и считаем этот ряд
рядом №1
2. Упорядочиваем по убыванию
ряды значений в обеих группах и заносим в таблицу:
|
1 – группа
испытуемых (первая выборка значений) |
2 – группа
испытуемых (вторая выборка значений) |
||||
|
номер |
Код
испытуемого |
Показатель
интеллекта |
номер |
Код
испытуемого |
Показатель
интеллекта |
|
|
|
136 |
|
|
|
|
2 |
|
136 |
|
|
|
|
3 |
|
136 |
|
|
|
|
4 |
|
135 |
|
|
|
|
|
|
134 |
|
|
|
|
6 |
|
132 |
1 |
|
132 |
|
7 |
|
132 |
|
|
|
|
8 |
|
132 |
|
|
|
|
9 |
|
132 |
|
|
|
|
10 |
|
131 |
|
|
|
|
11 |
|
129 |
|
|
|
|
12 |
|
127 |
2 |
|
127 |
|
|
|
|
3 |
|
126 |
|
|
|
|
4 |
|
126 |
|
13 |
|
125 |
|
|
|
|
|
|
|
5 |
|
123 |
|
|
|
|
6 |
|
123 |
|
14 |
|
122 |
|
|
|
|
|
|
|
7 |
|
120 |
|
|
|
|
8 |
|
120 |
|
|
|
|
9 |
|
120 |
|
|
|
|
10 |
|
119 |
|
|
|
|
11 |
|
116 |
|
|
|
|
12 |
|
115 |

3. Из таблицы определяем количество
значений первого ряда, которые больше максимального значения второго ряда: S1 =
5
4. Определяем количество
значений второго ряда, которые ниже минимального значения первого ряда: S2 = 6
5. Вычисляем Qэмп. по формуле: Qэмп
= S1 + S2.
6. Из таблиц находим
критические значения для данных размеров выборок.
3.
1) Меньшему значению начисляется меньший ранг.
Наименьшему значению
начисляется ранг 1.
Наибольшему значению начисляется
ранг, соответствующий количеству ранжируемых значений.
(Например, если n = 7, то наибольшее значение получит ранг 7.)
2) В случае если несколько значений равны, им начисляется
ранг, представляющий собой среднее значение из тех рангов, которые они получили
бы, если бы не были равны.
(Например, три наименьших
значения равны 10 секундам. Если бы время было измерено более точно, то,
вероятно, между этими значениями все-таки были бы отличия, скажем, 10,2; 10,3;
10,4 секунды. В этом случае они получили бы
соответственно ранги 1-й, 2-й и 3-й. Но поскольку эти три первых значения
равны, то получают средний ранг:
(1 + 2 + 3)/3
= 2.
Допустим, следующие два
значения равны 12 секундам. Они должны были бы получить ранги 4 и 5, но
поскольку равны, получают средний ранг: 4,5.
Не следует путать понятие ранга и
понятия порядкового номера! При ранжировании мы выбираем в
качестве следующего значения не следующее «по списку», а следующее по величине.)
3) Общая сумма рангов должна совпадать с
расчетной, которая вычисляется по
формуле:
S (Ri) =
N(N+1) / 2
Где N – общее количество ранжируемых наблюдений (значений).
Несовпадение реальной и расчетной суммы рангов
свидетельствует о допущенной ошибке при начислении рангов или при их
суммировании!
4.
Назначение критерия.
Критерий
предназначен для оценки различий между двумя
выборками по уровню какого-либо
признака, количественно измеренного. Он позволяет выявлять различия между малыми выборками, когда n1 и n2 больше или равны 3 (либо n1 = 2, а n2
тогда больше или равно 5.)
Описание критерия.
Метод
определяет, достаточно ли мала зона пересекающихся значений между двумя рядами.
Чем меньше эта область, тем более вероятно, что различия достоверны.
Эмпирическое (фактически полученное) значение
критерия U отражает то, насколько велика зона совпадения между рядами.
Чем меньше Uэмп., тем более вероятно, что различия
достоверны.
Гипотезы.
Но: Уровень признака в группе 2 не ниже
уровня признака в группе 1.
Н1: Уровень
признака в группе 2 ниже уровня признака в группе 1.
Графическое представление критерия U.
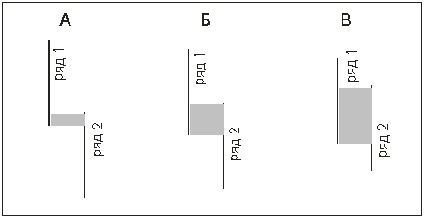
Рисунок 6
Вариант А. Второй ряд ниже
первого, и ряды почти не перекрещиваются. Область наложения слишком мала, чтобы
скрадывать различия между рядами.
Вариант
Б. Область пересекающихся областей достаточно обширна. Она может еще не
достигать критической величины, когда различия придется признать
несущественными.
Вариант
В. Второй ряд ниже первого, но область наложения настолько обширна, что
различия между рядами скрадываются.
Ограничения критерия U.
1. В каждой выборке должно быть не менее 3 наблюдений
или, в крайнем случае, допускается соотношение 2 к 5 или более.
2. В каждой выборке должно быть не более 60 наблюдений.
3.
Алгоритм подсчета критерия U –
Манна-Уитни.
1.
Перенести все
данные выборок на индивидуальные карточки (на которых цветом или как-то еще
будет отражено, к какой из выборок принадлежит значение).
2.
Разложить все карточки
в общий ряд по мере нарастания признака, не считаясь с тем, к какой выборке они
относятся.
3.
Проранжировать
(согласно алгоритму ранжирования) значения на карточках, приписывая
меньшему значению меньший ранг. Всего рангов должно быть n1 + n2 (объем первой
выборки + объем второй выборки).
4.
Заново разложить
карточки в два ряда, по признаку принадлежности к выборке 1 или выборке 2.
5.
Подсчитать сумму
рангов отдельно на карточках группы 1 и группы 2. Проверить совпадение общей
суммы рангов с расчетной.
6.
Определить большую из двух ранговых сумм.
7.
Определить
значение U по формуле:
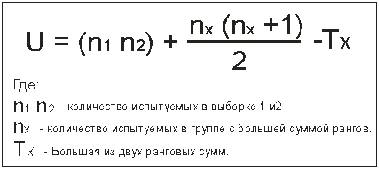
8.
Определить из таблиц критические значения U, в соответствии с этим, принять либо
отклонить гипотезу Но.
5.
Назначение критерия.
Критерий знаков предназначен для установления общего
направления сдвига исследуемого признака. Он позволяет установить, в какую
сторону в выборке в целом изменяются значения признака при переходе от первого
измерения ко второму.
Описание критерия.
Критерий применим как к тем изменениям, которые могут
быть определены только качественно (например, изменение отношения к чему-либо),
так и к тем, которые могут быть измерены количественно (например, сокращение
времени работы над заданием после экспериментального воздействия).
Под сдвигами понимается разница между значением n-ного
наблюдения в первом и втором измерении. Иными словами, сдвиг – это разница
между тем результатом, который показал n-ный испытуемый из выборки до и после
экспериментального воздействия. В ходе эксперимента может стать видно, что, к
примеру, у большинства испытуемых сдвиг
произошел в положительную сторону (усиление признака; в ту сторону, которую
предполагал исследователь и т.п.). Производится подсчет положительных,
отрицательных и нулевых сдвигов (изменений не зафиксировано), затем последние
исключаются из рассмотрения, что уменьшает фактический объем выборки. Согласно
табличным данным, производится сопоставление и определение достоверности
различий.
Преобладающие сдвиги принято называть «типичными»,
сдвиги в противоположную сторону – «нетипичными».
Гипотезы.
Но. Преобладание направления сдвига является случайным.
Н1. Преобладание направления сдвига не является случайным.
Ограничения критерия.
Объем
выборки может находиться в диапазоне от 5 до 300 элементов.
Алгоритм подсчета G – критерия знаков.
- Подсчитать
количество нулевых сдвигов и исключить их из рассмотрения. (При этом n уменьшится, и не должно стать меньше
5).
- Определить
преобладающее направление изменений. Считать сдвиги в преобладающем
направлении «типичными».
- Определить
количество «нетипичных» сдвигов, считать это число эмпирическим
значением G.
- Определить из таблиц
критическое значение для данного объема выборки и сопоставить с полученным
эмпирическим значением G. В случае, если эмпирическое число меньше или равно
критическому, сдвиг в типичную сторону может считаться достоверным.
6.
Назначение критерия.
Критерий предназначен для сопоставления показателей,
измеренных в двух разных условиях на одной и той же выборке испытуемых. Он
позволяет установить не только направленность изменений, но и их выраженность,
то есть, способен определить, является ли сдвиг показателей в одном направлении
более интенсивным, чем в другом.
Описание критерия.
Критерий применим в тех случаях, когда признаки
измерены, по крайней мере, в порядковой шкале. Целесообразно применять данный
критерий, когда величина самих сдвигов варьирует в некотором диапазоне (10-15%
от их величины). Это объясняется тем, что разброс значений сдвигов должен быть
таким, чтобы появлялась возможность их ранжирования. В случае если сдвиги
незначительно отличаются между собой, и принимают какие-то конечные значения,
например. +1, -1 и 0, формальных препятствий к применению критерия нет, но,
ввиду большого числа одинаковых рангов, ранжирование утрачивает смысл, и те же
результаты проще было бы получить с помощью критерия знаков.
Суть метода состоит в том, что мы сопоставляем
абсолютные величины выраженности сдвигов в том или ином направлении. Для этого
сначала все абсолютные величины сдвигов ранжируются, а потом суммируются ранги.
Если сдвиги в ту или иную сторону происходят случайно, то и суммы их рангов окажутся примерно равны. Если же интенсивность сдвигов в
одну сторону больше, то сумма рангов абсолютных значений сдвигов в
противоположную сторону будет значительно ниже, чем это могло бы быть при
случайных изменениях.
Сдвиг в более часто встречающемся направлении принято
считать «типичным», и наоборот.
Гипотезы.
Но. Интенсивность сдвигов в типичном направлении не превосходит
интенсивности сдвигов в нетипичном направлении.
Н1. Интенсивность сдвигов в типичном направлении
превышает интенсивность сдвигов в нетипичном направлении.
Графическое представление критерия.
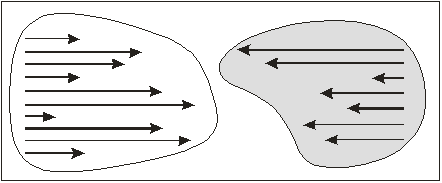
Рисунок 7
Графически критерий Вилкоксона можно представить в виде
двух «облачных фронтов», где количество стрелок отражает количество сдвигов,
их направление – направление сдвигов, а
длина – абсолютную величину сдвига, то есть разницы между значениями в первом и
втором измерениях.
Ограничения критерия.
Объем
выборки – от 5 до 50 элементов.
Нулевые
сдвиги исключаются из рассмотрения. (Это требование можно
обойти, переформулировав вид гипотезы. Например: сдвиг в сторону увеличения
значений превышает сдвиг в сторону их уменьшения и тенденцию к сохранению на
прежнем уровне.)
Алгоритм вычисления Т – критерия
Вилкоксона.
- Составить список
испытуемых в любом порядке, например, алфавитном.
- Вычислить разность
между индивидуальными значениями во втором и первом замерах. Определить,
что будет считаться типичным сдвигом.
- Согласно алгоритму
ранжирования, проранжировать абсолютные величины разностей, начисляя
меньшему значению меньший ранг, и проверить совпадение полученной суммы
рангов с расчетной.
- Отметить каким-либо
способом ранги, соответствующие сдвигам в нетипичном направлении.
Подсчитать их сумму Т.
- Определить
критические значения Т для
данного объема выборки. Если Т-эмп. меньше или равен Т-кр. – сдвиг в
«типичную» сторону достоверно преобладает.
7.
Назначение критерия.
Критерий
применяется в двух целях:
1) для сопоставления эмпирического распределения признака
с теоретическим;
2) для сопоставления двух или более эмпирических
распределений одного и того же признака.
Описание критерия.
Критерий c2 отвечает
на вопрос о том, с одинаковой ли частотой встречаются разные значения признака
в эмпирическом и теоретическом распределениях или в двух или более эмпирических
распределениях.
Метод
позволяет сопоставлять распределения признаков, представленных в любой шкале,
начиная от шкалы наименований. В самом простом случае «есть результат – нет
результата» уже можно пользоваться данным критерием.
Гипотезы. Три варианта:
1) Полученное эмпирическое распределение признака не
отличается (Но)/ отличается (Н1) от
теоретического (например, равномерного) распределения.
2) Эмпирическое распределение 1 не отличается (Но)/ отличается (Н1) от эмпирического распределения 2.
3) Эмпирические распределения 1,2,3 не отличаются (Но)/ отличаются (Н1) между собой.
Алгоритм расчета критерия.
- Занести в таблицу
наименования разрядов и соответствующие им эмпирические частоты (первый
столбец).
- Рядом с каждой
эмпирической частотой записать теоретическую частоту (второй столбец).
- Подсчитать разности между
эмпирической и теоретической частотой по каждому разряду (строке) и
записать их в третий столбец.
- Определить число
степеней свободы по формуле: ν = к
- 1, где к – количество разрядов признака.
- Возвести в квадрат
полученные разности, и занести их в четвертый столбец.
- Разделить полученные
квадраты разностей на теоретическую частоту и записать результаты в пятый
столбец.
- Просуммировать
значения пятого столбца. Полученную сумму обозначить как c2 эмп.
- Определить из таблиц
критические значения для данного числа степеней свободы, и на основании
полученных значений сделать вывод о достоверности расхождений между
распределениями.
|
Разряды. |
Эмпирическая частота |
Теоретическая частота |
f эмп. I -
f т. |
(f эмп. I - f т. )2 |
(f эмп. I - f т. )2/ fт |
|
1 2 3 . . . N |
|
|
|
|
|
|
Суммы. |
|
|
|
|
|
Алгоритм вычислений так же
выражается формулой:
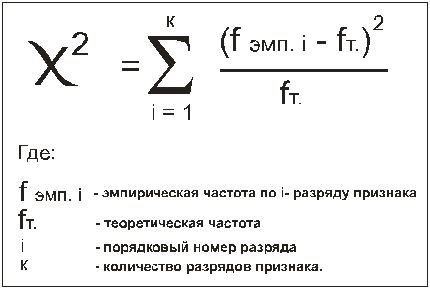
Графическое представление критерия.
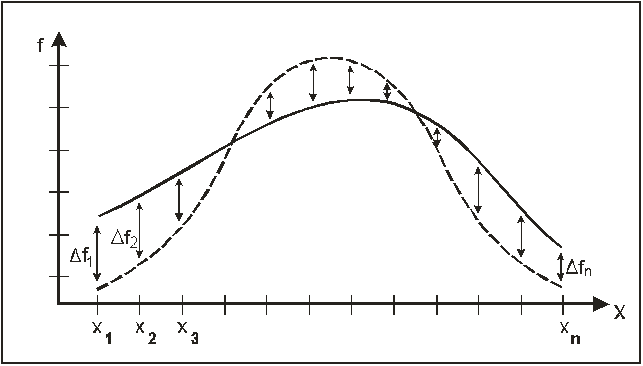
Рисунок 8
Рисунок 8 иллюстрирует суть операций, производимых в
рамках критерия. Штриховая линия – нормальное распределение (или любое другое),
с которым сравнивается наше эмпирическое распределение (сплошная линия). На оси
абсцисс представлены все значения случайной величины и распределены в порядке
возрастания. Ось ординат – частота встречаемости каждого
значения. ∆f – это разница между частотой, с
которой встретилось данное значение и частотой, с которой должно было встретиться,
если бы эмпирическое распределение соответствовало тому, с которым мы его
сопоставляем.
8.
l - критерий Колмогорова-Смирнова.
Назначение критерия.
Критерий предназначен для сопоставления двух
распределений: а) эмпирического с теоретическим; б) одного эмпирического
распределения с другим эмпирическим распределением.
Критерий позволяет найти точку, в которой сумма
накопленных расхождений между двумя распределениями является наибольшей и
оценить достоверность этого расхождения.
Описание критерия.
Здесь сопоставляются сначала частоты по первому
разряду, потом по сумме первого и второго разрядов, потом по сумме первого,
второго и третьего разрядов, и т.д. Таким образом, мы сопоставляем всякий раз
накопленные к данному разряду частоты.
Если различия между данными распределениями
существенны, то в какой-то момент
разность накопленных частот достигнет критического значения, и мы сможем
признать различия статистически достоверными. В формулу критерия λ
включается эта разность. Чем больше эмпирическое значение λ, тем более
существенны различия.
Гипотезы.
Различия между двумя
распределениями недостоверны (Но) /
достоверны (Н1) (судя по точке максимально накопленного расхождения
между ними).
Графическое представление критерия.
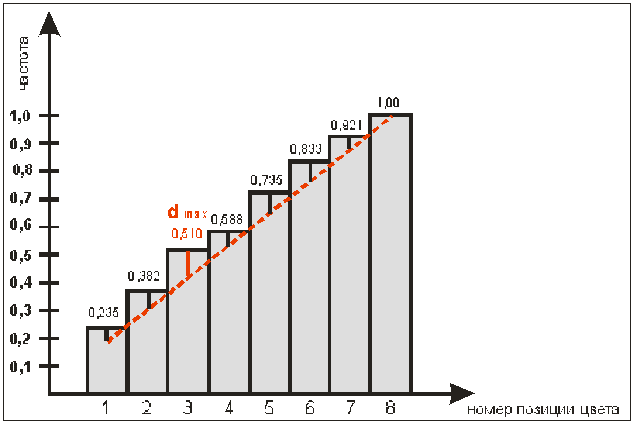
Рисунок 9.
(Пунктирной линией представлены значения частот,
которые наблюдались бы в случае, если бы распределение являлось равномерным, то
есть таким, с которым мы и сравниваем данное эмпирическое распределение.)
Рисунок 10 предназначен для облегчения понимания производимых действий.
Распределение, с которым мы проводим сравнение, представлено здесь в виде
«второго слоя» (темно-серая гистограмма).
Его мы мысленно накладываем на первый (светло-серая гистограмма).
Несовпадающие (неперекрывающиеся) области каждой пары столбцов и будут искомой
величиной dк.
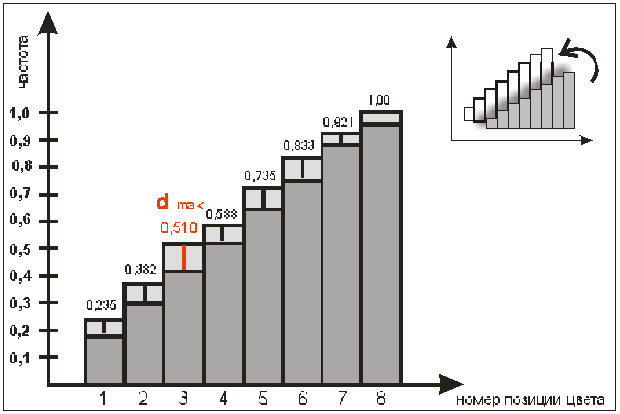
Рисунок 10.
Пример: распределение выбора желтого цвета в
8-цветовом тесте Люшера. Каждый цвет (в данном случае – желтый) теоретически может
ставиться человеком на любую позицию – от первой до восьмой, однако,
большинство ставит его на одну из трех первых позиций. Данный критерий
позволяет определить расхождение между теоретической частотой появления цвета
на данной позиции и фактически полученной частотой. Иными словами, критерий
Колмогорова-Смирнова позволяет узнать, достоверно ли данное эмпирическое
распределение отличается от теоретического, например,
от нормального.
На
рисунке столбцами представлены относительные частоты попадания желтого цвета
сначала на первую позицию, затем на первую и вторую позицию, затем на 1,2 и 3-ю
позиции, и т.д.: на данную позицию + все
предыдущие. Видно, что высота столбцов постоянно возрастает, так как они
отражают относительные частоты, накопленные к данной позиции. Например, столбец
на 3-й позиции имеет высоту 0,51. Это означает, что на первые три позиции
желтый цвет попадает в 51% всех случаев. Прерывистой линией соединены точки,
отражающие накопленные частоты, которые наблюдались бы, если бы желтый цвет попадал
с равной вероятностью на каждую из восьми позиций. Расхождения обозначаются как
d. Максимальное расхождение
обозначено, как d max. Именно эта третья позиция цвета и
является переломной точкой, определяющей, достоверно ли отличается данное
эмпирическое распределение от равномерного.
Еще один пример использовакния критерия.
Пример маркетологический.

Рисунок 10-а
Пусть мы производим некий товар и имеем
четырех конкурентов, выпускающих такое же изделие с близкими свойствами,
продающих его по сопоставимой цене. Иными словами, наш товар и аналоги конкурентов
приблизительно одинаковы по всем свойствам и по подходу к его продаже.
Спрашивается: с равной ли вероятностью покупаются все разновидности этого
изделия? То есть, с одинаковой ли частотой покупатели приобретают товар,
выпускаемый нами и каждым конкурентом? Если это окажется не так, и
распределение покупаемости товаров будет отличаться от равномерного,
- стало быть, какой-то образец по какому-то параметру предпочтительнее. Дальнейшая
задача – определять, что же это за параметр, и ответ на такой вопрос выходит за
пределы стастического исследования, но первая стадия задачи решается именно
методом Колмогорова-Смирнова (можно и Пирсона).
Эксперимент организовывался бы при этих
условиях так: N респондентов просили бы расставить все товары в порядке предпочтения (то есть – проранжировать).
Для каждого товара тогда производим отдельный расчет и рисуем отдельную гистограмму. На такой
гистограмме следует отложить:
- в
первом столбце – сколько раз наш (или конкурирующий) товар был избран на первое
место?
-
во втором столбце – сколько – на первое и второе вместе?
-
в третьем столбце – сколько – на первое + второе + третье?
-
в четвертом столбце – а сколько – на первое + второе + третье + четвертое?
- в
пятом столбце – и, наконец, - сколько – на первое + второе + третье + четвертое
+ пятое место?
Вторично эта процедура проводится для
идеального случая, в котором мы исходим их предположения, что все товары избираются
на первое место (то есть – покупаются) одинаково
часто. Гистограмма тогда выглядела бы лесенкой, у которой все ступеньки
возрастают на одинаковую величину.
Заключительный этап – сопоставление разницы
между каждой парой столбцов гистограммы. Наибольшая разница и укажет, число d max.
***
Ограничения критерия.
Критерий
требует достаточно большой выборки при сопоставлении двух эмпирических
распределений (больше или равно 50). При сопоставлении эмпирического
распределения с теоретическим допускается n больше или
равно 5.
Алгоритм расчета абсолютной величины
разности d
между эмпирическим и равномерным
распределениями.
1. Занести в таблицу наименования разрядов и
соответствующие им эмпирические частоты (первый столбец).
2. Подсчитать относительные эмпирические частоты для
каждого разряда по формуле:
f* эмп. = f / n, где: fэмп. – эмпирическая частота по данному разряду, n – общее количество наблюдений.
Занести результаты во второй столбец.
3. Подсчитать накопленные эмпирические частоты по
формуле: Σf*j = Σf*j-1 + f* j, где Σf*j-1 - частота, накопленная на предыдущих разрядах; j – порядковый номер разряда; f* j –
эмпирическая частота данного j-го разряда. Занести результаты в третий столбец
таблицы.
4. Подсчитать накопленные теоретические частоты для
каждого разряда по формуле:
Σf*тj = Σf*тj-1 + f* тj, где: Σf*тj-1 -
теоретическая частота, накопленная на предыдущих разрядах; j – порядковый номер разряда;
f* тj – теоретическая
частота данного разряда. Занести результаты в четвертый столбец таблицы.
5. Вычислить разности между эмпирическими и
теоретическими накопленными частотами по каждому разряду.
6. Записать в пятый столбец абсолютные величины
полученных разностей (без учета их знака). Обозначить их как d.
7. Определить по пятому столбцу наибольшую величину
разности d max.
8. Исходя из таблиц, определить критическое значение d max для данного числа n наблюдений.
Если полученное эмпирическое число d max
превышает критическое – различия достоверны.
9.
Критерий j* - угловое преобразование Фишера.
Назначение критерия.
Критерий предназначен для сопоставления двух выборок
по частоте встречаемости интересующего исследователя эффекта.
Описание критерия.
Критерий оценивает достоверность различий между
процентными долями двух выборок, в которых зарегистрирован интересующий нас
эффект. Суть углового преобразования Фишера состоит в переводе процентных долей
в величины центрального угла, выраженные
в радианах. Большей процентной
доле будет соответствовать большее значение угла φ, и наоборот. Поскольку в уравнение включена
тригонометрическая функция, зависимость между φ и процентной долей будет
нелинейной. Она выражается уравнением:
φ = 2 arcsin (√ P) (арксинус
корень из P)
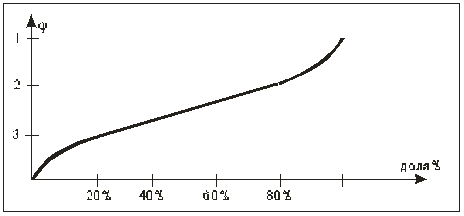
Рисунок 11.
(На графике показана зависимость угла φ от
процентной доли.)
При увеличении расхождения между углами φ1 и
φ2 (в первой и второй выборках) значение критерия φ* возрастает. Чем больше эта величина, тем более вероятно,
что различия достоверны.
Гипотезы.
Доля случаев, в которых проявляется исследуемый
эффект, в выборке 1 не больше (Но)
\ больше (Н1), чем в выборке 2.
Графическое
представление критерия φ*.
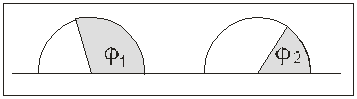
Рисунок 12.
Предположим, что имеются две группы людей, являющихся
экспертами в данной области. Обеим группам предложено оценить некую проективную
методику по двухбалльной системе (допускаю / не
допускаю к использованию). Требуется определить, имеются ли различия между
оценками двух групп. (Это может быть актуально, если в одной из групп, скажем,
находятся специалисты по психодиакностике, а во второй –
эксперты-психоаналитики и т.п.). На данной иллюстрации эти соотношения
представлены двумя серыми областями – углами φ1 и φ2. За 100% выборки принимается угол, равный
π (3,142), что в радианной мере соответствует половине круга.
Критерий позволяет определить, действительно ли один
из углов статистически достоверно превосходит другой при данных объемах
выборки.
Ограничения
критерия.
1. Ни одна из сопоставляемых долей не должна быть равной
нулю.
2. Число элементов выборки не ограничено сверху. Нижний
предел – 2 наблюдения в одной из выборок, при условии соблюдения соотношений:
|
Первая
выборка |
Вторая
выборка |
|
2 |
Не менее 30 |
|
3 |
Не менее 7 |
|
4 |
Не менее 5 |
|
При n1; n2 больше или равно 5 возможны любые
сочетания. |
|
Возможности
использования критерия.
1. Сопоставление выборок по качественно определяемому
признаку.
2. Сопоставление выборок по количественно измеряемому
признаку.
3. Сопоставление выборок и по уровню, и по распределению
признака.
Алгоритм расчета критерия φ*.
- Определить те
значения признака, которые будут критерием для разделения испытуемых на
тех, у кого есть эффект и нет эффекта. (Если
признак измерен количественно, следует использовать критерий λ –
Колмогорова-Смирнова для поиска оптимальной точки разделения.)
- Начертить
четырехклеточную таблицу из двух столбцов и двух строк:
|
Есть эффект 1 выборка |
Нет эффекта 1 выборка |
|
Есть эффект 2 выборка |
Нет эффекта 2 выборка |
- Подсчитать
количества значений, соответствующих ячейкам этой таблицы, и занести числа
в таблицу. Сумма чисел по строкам должна совпадать с объемом первой и второй
выборки - соответственно.
- Подсчитать
процентные доли значений, имеющих эффект для первой и второй выборки путем
деления содержимого ячеек левого столбца на объем соответствующей выборки.
Подписать к таблице (например, в скобках) полученные числа, расположив их
в соответствующих местах:
|
Есть эффект 1 выборка (……….%) |
Нет эффекта 1 выборка |
|
Есть эффект 2 выборка (……….%) |
Нет эффекта 2 выборка |
- Проверить, не
равняется ли одна из сопоставляемых долей нулю.
- Определить из
справочных таблиц или по формуле φ
= arcsin (√
P) значение угла для каждой из сопоставляемых
процентных долей.
- Подсчитать
эмпирическое значение φ* по
формуле:
φ* =
(φ1 – φ2) √ n1 n2 / (n1 + n2)
 По таблицам сопоставить результат с критическим
значением.
По таблицам сопоставить результат с критическим
значением.
Тригонометрическая справка.
Угловое преобразование Фишера позволяет перевести
процентные доли, имеющие распределение, отличное от нормального, в величину
угла φ. Это распределение уже
близко к нормальному, и позволяет использовать параметрические
методы статистического анализа.
Углы φ измеряются в радианах. Радиан – угол,
являющийся центральным для дуги, длина которой равна радиусу окружности. 1
радиан примерно равен 57 градусов. (57о
17'44'').
Синусом угла треугольника называется отношение противолежащего катета к гипотенузе (